Help with Discerner
This information will help you interpret text comparisons and use the Discerner interface more effectively. If you have questions, please contact us. Here are the available help sections:
Line Comparison
A line comparison consists of matches between words in a single line of a primary text and words in a secondary text. Below is an example of a line comparison. A line of the primary text is on the left. A line of the secondary text is on the right. Matches are in red.

Each line has a header. The header includes a magnitude, a reference, and an expand or collapse icon. The magnitude is a number in a colored oval that indicates the combined strength of matches between words in the primary and secondary lines. The reference is a text name and line number that identifies the sequence of the line within its text. And the expand or collapse icon is coupled arrows pointing inward or outward that enable you to show or hide the words in the line.
Each line comparison has a colored border along the left side. The color corresponds to the color of the magnitude of the primary line.
Below is another example of a line comparison. A line of the primary text is on the left. Its header indicates that it is a strong match with the secondary lines at magnitude 15+. It is line one in "Article 2 Section 4". And it is expanded to show the words of the line.
Three lines of the secondary text are on the right. The first is line five of "Federalist 69", and it is a strong match with the primary line at magnitude 15+. The second is line seven of "Federalist 69", and it is a weak match with the primary line at magnitude 13. The third is line ten of "Federalist 69". It is also a weak match with the primary line at magnitude 13. And it is collapsed to hide the words of the line.

Section Comparison
A section comparison consists of one or more line comparisons and their aggregated statistics for a single section of a primary text and a secondary text. Each section comparison has a header, a summary, and a line list.
The header includes a title and breadcrumbs. The title identifies the relevant primary section and secondary text. The breadcrumbs link to any text comparisons of which the section comparison may be a part.
Below is an example with two breadcrumbs. The title is "Comparison of United States Constitution (1997) Article 2 Section 1 to Federalist Papers". It is part of "Comparison of United States Constitution (1997) Article 2 to Federalist Papers", which is part of "Comparison of United States Constitution (1997) to Federalist Papers".

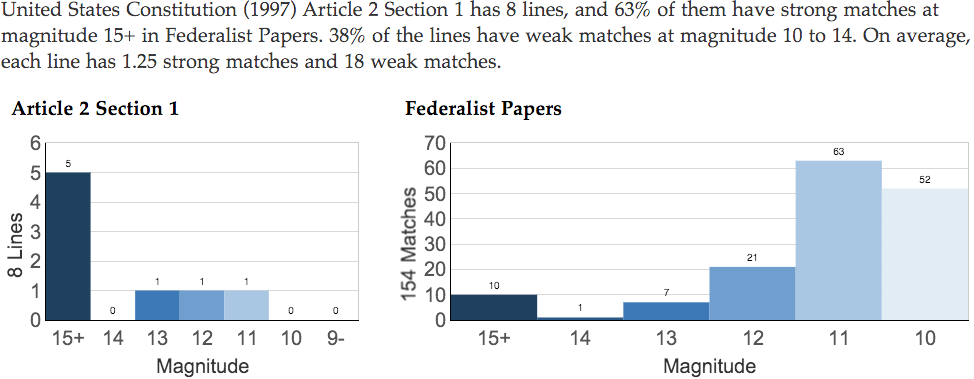
The summary of a section comparison includes a paragraph and two charts. The paragraph describes the content of the charts. The chart on the left shows the number of lines in the primary section, with each line categorized by the magnitude of its strongest match to lines in the secondary text. The chart on the right shows the number of matches in the secondary text, with each categorized by its magnitude.
Below is an example. The primary section is "Article 2 Section 1". It has eight lines. Five of the lines have strong matches in the secondary text at magnitude 15+. Three of the lines have weak matches in the secondary text at magnitude 13, 12, and 11. The secondary text is "Federalist Papers". It has 154 matches with the primary section. Ten are strong matches at magnitude 15+. The remainder are weak matches at magnitude 10 to 14.
After its summary, a section comparison presents a line list.
Line List
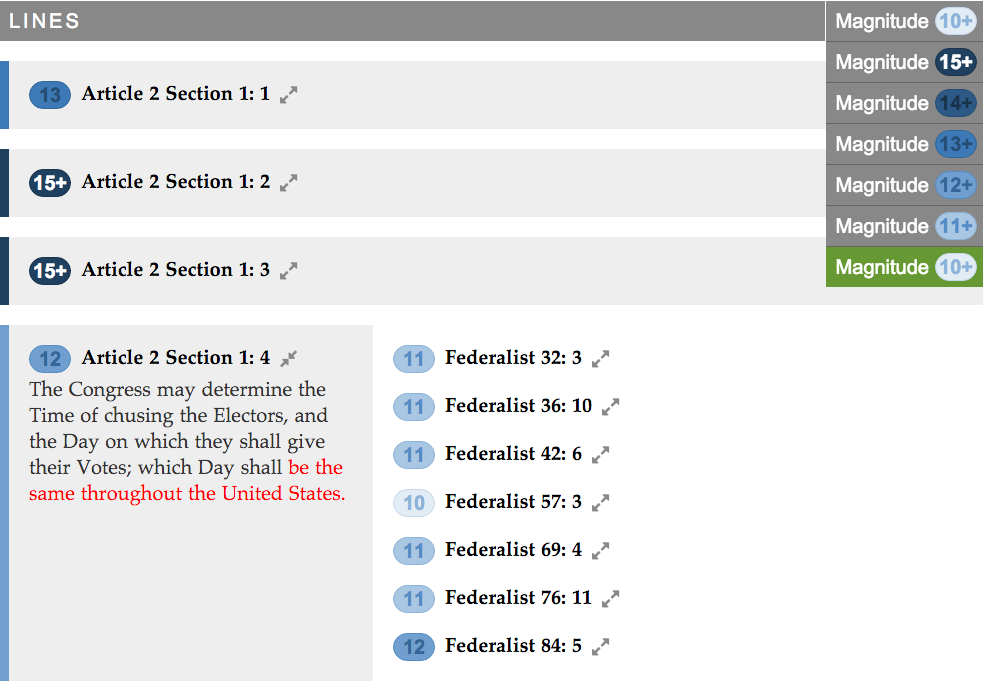
A line list presents all the line comparisons that are part of a section comparison. The list has a filter that enables you to set the lower bound of magnitude to show. By default, the filter shows only strong matches at magnitude 15+. Here is an example of a line list with all the primary lines collapsed:

To change the filter, you may select a lower bound of magnitude from the dropdown menu on the right. Afterwards, additional primary and secondary lines will appear as appropriate. Here is a partial example of the filter set to show all matches at magnitude 10+, with one primary line expanded and all of its secondary lines collapsed:
Text Comparison
A text comparison consists of one or more section comparisons and their aggregated statistics for a primary text and a secondary text. Each text comparison has a header, a summary, and either a line list or a section table.
The header of a text comparison includes a title and breadcrumbs. The title identifies the relevant primary and secondary texts. The breadcrumbs link to any text comparisons of which the text comparison may be a part. A text comparison may be a section in another text comparison.
Below is an example with one breadcrumb. The title is "Comparison of United States Constitution (1997) Article 2 to Federalist Papers". It is part of the comparison of "United States Constitution (1997) to Federalist Papers".

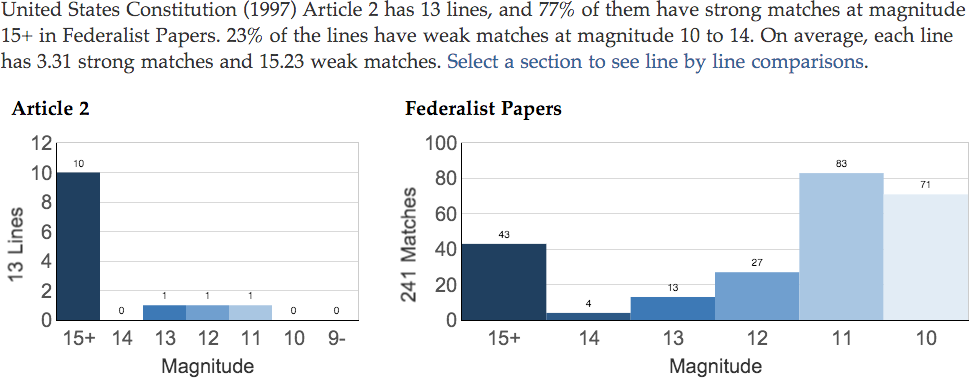
The summary of a text comparison includes a paragraph and two charts. The paragraph describes the content of the charts. The chart on the left shows the number of lines in the primary text, with each line categorized by the magnitude of its strongest match to lines in the secondary text. The chart on the right shows the number of matches in the secondary text, with each categorized by its magnitude.
Below is an example. The primary text is "Article 2". It has thirteen lines. Ten of the lines have strong matches in the secondary text at magnitude 15+. Three of the lines have weak matches in the secondary text at magnitude 13, 12, and 11. The secondary text is "Federalist Papers". It has 241 matches with the primary text. 43 are strong matches at magnitude 15+. The remainder are weak matches at magnitude 10 to 14.
After its summary, a text comparison presents either a line list or a section table. If its primary text has only one section, the text comparison presents a line list. If its primary text has more than one section, the text comparison presents a section table.
Section Table
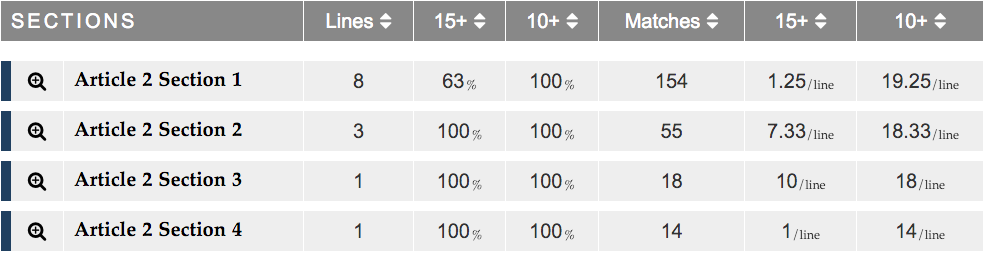
A section table presents all the section comparisons that are part of a text comparison. The table has a row for each section of the primary text and columns that indicate in various ways the strength of similarities between primary sections and the secondary text. A row may have up to seven columns:
- The first column shows the name of the primary section, and the color of its left border corresponds to the magnitude of its strongest match.
- The "Lines" column shows the number of lines in the primary section.
- The first "15+" column shows the percentage of lines in the primary section with strong matches at magnitude 15+ in the secondary text.
- The first "10+" column shows the percentage of lines in the primary section with any matches at magnitude 10+ in the secondary text.
- The "Matches" column shows the number of matches in the secondary text.
- The second "15+" column shows the average number of strong matches at magnitude 15+ in the secondary text for each line in the primary section.
- The second "10+" column shows the average number of any matches at magnitude 10+ in the secondary text for each line in the primary section.
Below is an example of a section table. The first row is for primary section "Article 2 Section 1". It has eight lines. 63% of its lines have strong matches at magnitude 15+ in the secondary text. And 100% of its lines have matches at magnitude 10+. The primary section has 154 matches in the secondary text. On average, there are 1.25 strong matches at magnitude 15+ in the secondary text for each line in the primary section. And, on average, there are 19.25 matches at magnitude 10+ for each line in the primary section.
The table has column headers that enable you to sort rows by values in a particular column. By default, the table sorts rows by the sequence in which primary sections appear in their text. To sort by another column, you may select a column header once to sort in descending order or twice to sort in ascending order. To restore the table to default sorting, you may select the first column header. Here is an example of a section table sorted by its second "15+" column in descending order:
Magnitude
A magnitude is a number that indicates the strength of a match between one or more words in a primary text and one or more words in a secondary text. A higher magnitude indicates a stronger match.
Matches at a given magnitude are approximately ten times stronger than those at the magnitude immediately below. For example, those at magnitude 10 are about ten times stronger than those at magnitude 9. Those at magnitude 11 are about a hundred times stronger than those at magnitude 9. And those at magnitude 15 are about a million times stronger than those at magnitude 9.
Matches at magnitude 15 and higher are "strong". Those at magnitude 10 to 14 are "weak". And those at magnitude 9 and lower are "insignificant".
When combined with "+" and "-" signs, magnitude numbers indicate ranges or bounds of magnitude. For example, magnitude 15 and higher is "15+". Magnitude 10 to 14 is "10-14". Magnitude 10 and higher is "10+". And magnitude 9 and lower is "9-".
Here are the steps for calculating a magnitude:
- Begin with the probability of a match
- Calculate the common logarithm of the probability
- Round the common logarithm to the nearest integer
- End with the absolute value of the nearest integer
For example, if the probability of a given match is 0.00000000000005 then its common logarithm is -13.3010299957. Its nearest integer is -13. And its absolute value is 13, which is also its magnitude.
Below are some approximate correspondences between magnitudes and probability ranges. To simplify, you might think of a magnitude as the number of zeros after the decimal in its probability.
- Magnitude 10 begins near 0.0000000003 and ends near 0.00000000004 (around ten zeros)
- Magnitude 11 begins near 0.00000000003 and ends near 0.000000000004 (around eleven zeros)
- Magnitude 12 begins near 0.000000000003 and ends near 0.0000000000004 (around twelve zeros)
- Magnitude 13 begins near 0.0000000000003 and ends near 0.00000000000004 (around thirteen zeros)
- Magnitude 14 begins near 0.00000000000003 and ends near 0.000000000000004 (around fourteen zeros)
- Magnitude 15+ begins near 0.000000000000003 (around fifteen zeros or more)
Each line comparison inherits the highest magnitude among its matches. The magnitude appears in a colored oval. Below are two examples in a line list. The first has matches in six secondary lines. One of them has a strong match at magnitude 15+. The others have weak matches at magnitude 11. So the primary line indicates magnitude 15+. Likewise, the primary line of the second line comparison indicates magnitude 13, although it also has weaker matches at magnitude 10.

The color associated with a line comparison corresponds to its magnitude. The color appears in the oval at the front of its line headers, and as the color of its left border, as illustrated in the example above. The color also appears in the bars of charts that aggregate statistics for text comparisons and section comparisons, as illustrated in the example below. Note how the dark blue in the 15+ bars below corresponds to the dark blue in the 15+ ovals above.
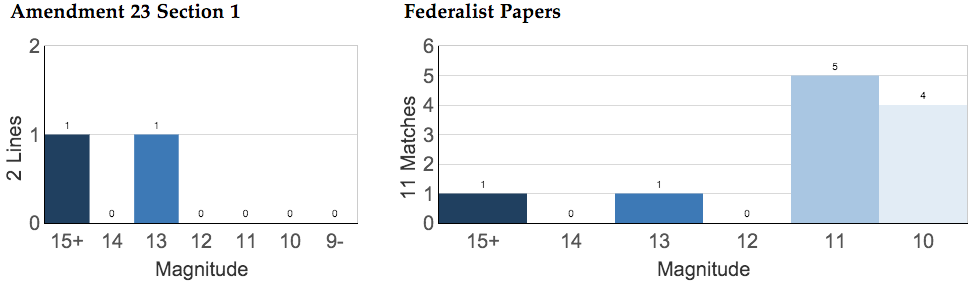
In section tables, each section comparison inherits the color associated with the highest magnitude among its line comparisons. The color appears in the left border of the first column, as illustrated in the example below. Primary section "Amendment 23 Section 1" has a dark blue left border, indicating a strong match. And primary section "Amendment 23 Section 2" has a light blue left border, indicating a weak match.

Match
A match is a statistical correspondence between one or more words near each other in a primary text and one or more words near each other in a secondary text. Here are the steps for identifying a match:
- Segment both texts into sets of contiguous words (n-grams) ranging in size from 1 to 9 words
- Compare each set of a given size from one text to each set of the same size from the other text
- Identify each comparison with one or more identical words in both of its sets as a match
Each match has a probability. Here are the steps for calculating the probability of a match:
- Calculate the frequencies at which identical words from the match appear in texts generally
- Calculate the probability of the combined frequencies within the set size of the match
The probability of each match corresponds with a magnitude that indicates its strength. A lower probability corresponds with a higher magnitude, indicating a stronger match.
A line comparison inherits the magnitude of the strongest match between words in its primary line and words in any of its secondary lines.
FAQ
Why do self-comparisons not match 100%?
A self-comparison uses a single text as both the primary text and the secondary text, comparing the text to itself. A self-comparison would match 100% if it compared all lines in the text to each other because a given line would always match itself perfectly. Such self-comparisons generally would not be useful. To make themselves useful, self-comparisons do not include comparisons of a given word to itself, but rather include only comparisons of a given word to all other words except itself.